


We’ve spilled a lot of ink on 14/16nm FinFET here at EE Journal. It is exciting stuff: bleeding-edge process technology and a fabulous new transistor structure; heck, it’s 3D without the glasses. There is no doubt that FinFET will be a difference maker in some high-profile products. As reality sets in, however, there is growing doubt with regards to the breadth of FinFET applicability. FinFET will make the transition from bleeding-edge to leading-edge, but it may not make the transition to mainstream anytime soon … perhaps never.
FinFETs certainly sound golden. Like most golden developments, there is a catch: FinFETs require more complex process technology than planar FETs, and, coupled with the mind-numbing 14/16nm geometries in play things get really, really complicated. We are talking quite literally about the most complex undertaking in the history of mankind, all hyperbole checked at the gate. And while that has tremendous cachet amongst us Silicon Valley types, unfortunately, it makes for expensive chips.
Mask sets are very expensive and wafers are priced at a serious premium; for the foreseeable future, the math proves that 14-nay-16nm FinFET is only for serious high-runners. Randomly rattling off likely OEMs: Intel, Qualcomm, Apple, Broadcom, Marvell, AMD, Nvidia, Altera and Xilinx. And not all of their new tapeouts, far from it, only their highest-of-high-runners or chips that simply cannot be manufactured on 20nm or 28nm. And that will be the state of affairs for quite some time, as the crossover curves versus the N-1 node look nothing like your father’s crossover curves.
As is my wont, I again find myself a few hundred words into an article having not yet touched on the title of said post. 28nm, finally! There was widespread acknowledgement from the outset that 28nm would be a “long-lived node.” As the last two years’ profusion of FinFET excitement has settled down, however, 28nm has emerged as more of an “asymptotic node.” A significant fraction of the semiconductor world will live on 28nm for a significantly longer-than-usual time, and the ramifications are seriously significant for the entire foundry model. “Inflection point” just doesn’t carry enough gravitas; “seismic shift” is more like it.
First, the good news: 28nm will be a richly enabled mode, with a full complement of value-added solutions (VAS): RF, NVM and high-voltage analog. The major foundries are rolling out 28nm RF processes this year; major foundries and OEMs are pouring energy into MRAM on 28nm with hoped-for 2015 production; high-voltage analog will arrive in various capabilities starting this year. All of these VAS options will, indeed, add customer-perceived value and enable the foundries to keep gross margins on 28nm healthy … for a time. Summarizing the good news: OEMs will be delighted with the process offerings on 28nm.
The above is “Moore’s Law as usual” applied to 28nm. Then there are the potential technology kickers that will further extend the node’s competitive lifetime.
Technology kicker #1 is our old friend FD-SOI, one of those innovations that has been “right around the corner” for fifteen years now. I could fill multiple posts with the what, why and why-not of FD-SOI; Wikipedia does as good a job as any if you are keen on details. (Your Google search will take you to some great stuff by ST: those are better tutorials, just keep in mind that the good people at ST have a dog in this fight. Indeed, you might say they are the only ones left with a dog in this fight.) Here’s the super-short version:
- Compared to bulk CMOS, FD-SOI makes for better FETs.
- Roughly speaking, 28nm FD-SOI offers very similar performance/power characteristics to 20nm bulk silicon.
- While the special FD-SOI wafers are slightly more expensive than their bulk CMOS counterparts, wafer processing is slightly simpler. If you squint a bit you can say that a die on 28nm FD-SOI costs roughly the same as on 28nm bulk CMOS.
I know what you’re thinking: “I want my FD-SOI … better performance/power and your chips for free!” (Apologies to Dire Straits.) Let’s try that again. You’re thinking “why on earth aren’t ALL 28nm products built on FD-SOI?” There are—surprise!—a few issues:
- Those special wafers? There is one company on the planet that manufactures them.
- While the planar FETs are manufactured using the same methodology as bulk CMOS, the N/P ratio is different for FD-SOI. That is to say, the ratio of NMOS-to-PMOS drive—never mind—the bottom line is that the design rules and libraries are different.
- Which is to say you cannot take a design—or blocks of IP, for that matter—done on bulk CMOS and drop it onto FD-SOI … well, you can, it just won’t work particularly well.
Throw the pros and cons in a Vitamix and you get optionality: FD-SOI provides a performance and/or power kicker on 28nm; do keep in mind that FD-SOI does nothing for die area. Earlier this year none other than Samsung became the latest company to say nice things about FD-SOI; should those kind words translate into wafer volume, FD-SOI’s long and tortured road to popularity would get a significant vote of confidence.
Closing note: there is NOTHING 28nm-specific about FD-SOI. You can rinse-and-repeat, building 20nm planar FD-SOI to score 14nm-like performance/power results. Indeed, there are those folks (mostly with French and Italian accents, go figure) who resolutely believe FinFETs should be manufactured on FD-SOI.
Technology kicker #2 is the broad toolbox of System-in-Package (SiP), namely 2.5D and 3D stacking. This is orthogonal to FD-SOI, coincidentally, in that it squarely addresses die-size and cost issues. There is a lot of VERY COOL stuff in this toolbox, such as Through Silicon Via (TSV, which to this day, I still wish were made using teenie Dremel tools).
As Xilinx demonstrated, one can use TSVs and silicon interposers to construct products that behave like impossibly large monolithic die. The beauty is that you can do so cost-effectively, because [a] the component die on the silicon interposer are small enough to yield and [b] the large silicon interposer is simple enough to yield as well.
Perhaps more interesting to the broader semiconductor universe: one can deploy 2.5D and 3D technology to construct products that behave like a yieldable-but-large-and-expensive die out of sweet-spot-yielding-smaller-and-cheaper die. And one need not use a (relatively) expensive silicon interposer; an organic substrate will do the trick in most cases.
Even more interesting: one can stack heterogeneous die, manufactured on completely different processes. All that bitching and whining from the analog designers over the ‘crappy’ process characterization? Copacetic, slide rule dudes: work your magic spells on 130nm high-resistivity SOI or whatever voodoo you chose; we’ll assemble it with the bulk CMOS 28nm logic die. And finally, finally we can stop hearing about embedded DRAM (eDRAM, “just around the corner” pretty much forever) and simply stack a perfectly good DRAM die.
The possibilities here are multi-fold: [a] build extremely complex products on 28nm in a cost-effective manner, products that would ‘normally’ require the next node due to die size, and [b] deliver systems encompassing very different process requirements without having to solve the dogs-and-cats-sleeping-together process issues. It bears repeating here as well: SiP techniques have no particular affinity with 28nm.
What we have here is a confluence of factors all conspiring to make 28nm the longest lived node in semiconductor history. Many, many products will remain on 28nm until the cows come home … and we haven’t seen a cow in Silicon Valley for an eternity.
With such a full menu available from multiple foundries, OEMs will be able to deliver fascinating and distinctive products and enjoy competitive wafer pricing. We will see a tremendous variety of innovative solutions living happily on 28nm for a very, very long time. Why the Rip van Winkle (minus the sleeping) timeframe? Three factors:
- The “new normal” crossover curves, that will keep 14/16nm out of reach for the majority of designs for the foreseeable future.
- The rich enablement that will make 28nm a “great destination” for a large fraction of new designs for the foreseeable future.
- The commoditization of 28nm process technology. So much for the “good news” portion of the article, as far as the foundries are concerned.
How quickly is 28nm being commoditized? Intel, Globalfoundries, Samsung, SMIC, TSMC, UMC … any questions? There is A LOT of 28nm capacity and the competitive pressures are increasing as SMIC and UMC ramp the node. That “new node smell” has already worn off.
All those new tapeouts will keep the capacity fully engaged, but at ever decreasing margins. This setup is a nasty combination punch to the foundries:
- 14/16nm FinFET consumed tens of billions of dollars of CapEx. The modest number of ultra-high runners will fill the capacity, but given the “count them on your fingers” (and toes) number of tapeouts per year, profitability will be in the oven a while.
- 28nm will truly be “Home, Sweet Node” for most leading-edge tapeouts for a prolonged period of time.
- Intense competitive pressure will squeeze 28nm margins to “new normal”—also known as “uncomfortable”—levels real-soon-now.
Or as a foundry might say:
- I just wrote a really, really big check and the ROI will take a long time to arrive.
- I’m going to have a ton of business on 28nm, but at squeezed margins.
Or simplifying further:
- How on EARTH am I going to pay for 10nm?
Prior to embarking on this article, I laid out my working hypothesis to industry veteran, mentor, ex-colleague and fellow bike rider Mike Noonen. Indeed, the discussion took place during a metric century (100km ride) … which made for periods of rather curt exchanges on the climbs, as we both weighed the tradeoff between conversation and actually breathing.
As fate would have it, both of our thought processes are very much aligned with the thesis outlined above. Mike summarizes brilliantly in a trio of graphs:
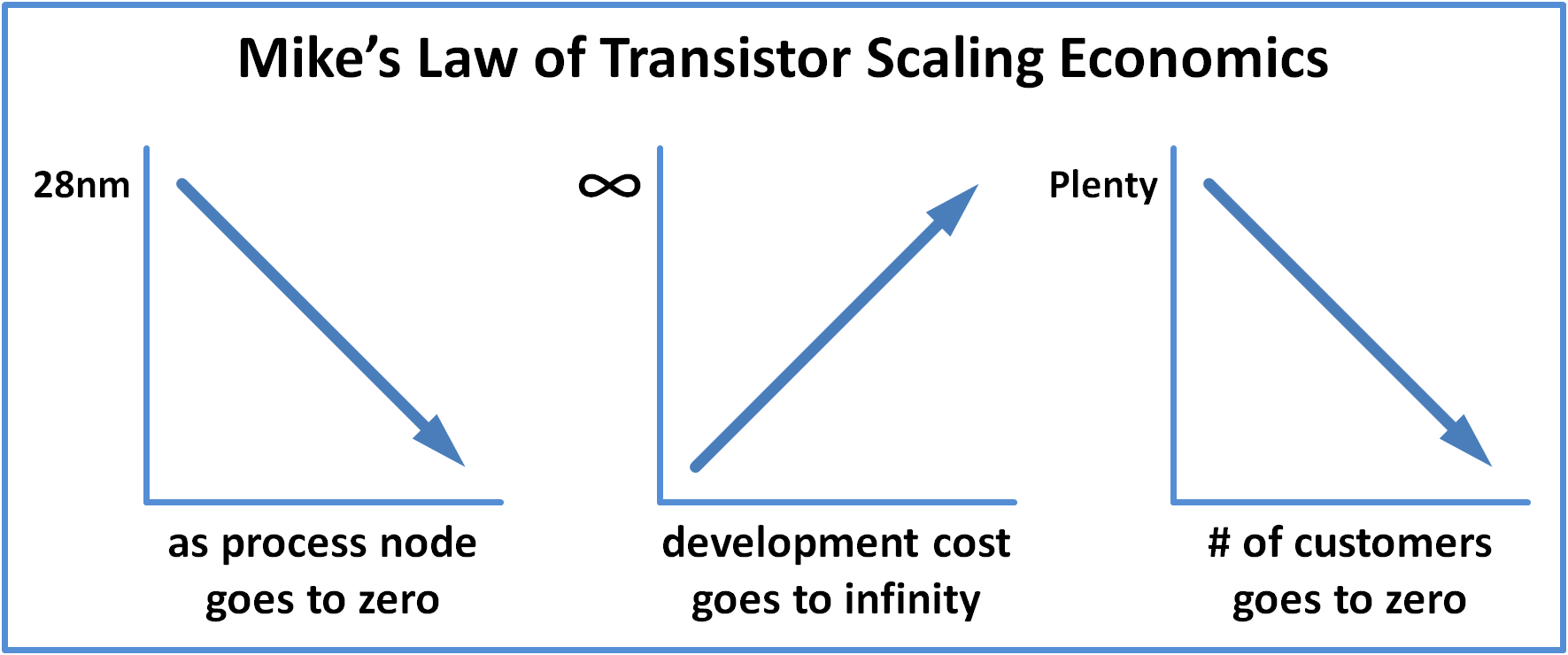
Minor digression: one of the GREAT things about working in marketing is that you can get away with showing graphs where neither of the axes have units. I’m fairly certain that the vertical axis on most if not all of the above graphs are log scale, but I’ll defer that detail to Mike.
I’m a tad surprised Mike didn’t add a fourth graph, declaring that the number of foundries on the bleeding-edge node goes to zero. This is the logical outcome of combining graphs 2 and 3: as costs skyrocket and the number of customer shrinks, nobody can fund the infinite cost of the next node.
The infinite-dollar question is obviously when does all this happen, or put another way, “when does the music stop?” Mike and I ran out of kilometers before we got to this line of inquiry, so here goes.
14/16nm FinFET will hoover many foundry coffers dry. The hoovering will be especially strong for those foundries that encounter potholes that delay full production.
Say what you will about Intel, one cannot cast aspersions on their manufacturing prowess. They have a proven track record of innovation and driving bleeding-edge nodes into production. They are a veritable machine … and that machine sounded like an asthmatic wheezing without its inhaler as it was bringing up 14nm. Credit where credit is due: Intel’s 14nm will be in full production (a Broadwell flavor or three) this year.
Intel weren’t just first to productize FinFET, they were first by a country mile. And they gained exceptional experience shipping Intel-class-volume. And these guys had a tough time with 14nm. So no disrespect to the very good people at TSMC, Samsung and Globalfoundries, but seriously dudes, you’ve got your work cut out for you on 14/16nm … to say nothing of 10nm, which will be the mother of all poker games. Were someone taking bets on the 10nm race, I’d put serious coinage on at least one of the aforementioned trio not making it to the finish line.
That brings us to 7nm, a node that makes 10nm look like a cakewalk. The fact that smart people think that EUV may be required on 7nm—and when I say “smart people” I mean that they were smart enough NOT to talk about EUV earlier—ought to be terrifying enough. If you haven’t yet had the fun of being scared out of your pants by EUV, check out this YouTube video from Cymer, the leader in EUV light sources. If you don’t have time to watch the video, here’s a money quote:
A high power laser evaporates a tin droplet, then heats the vapor to critical temperature where electrons are shed, leaving behind ions, which are further heated until they start emitting photons.
I’ve demonstrated that I am quite capable of making stuff up, but honestly, if tasked with scaring the pants off the semiconductor industry for Halloween I doubt I could match the above quote. And the aforementioned video barely touches on the petrifying nightmare that is EUV mask making, mask inspection, mask repair … aaaAAAHHH SCARY.
The alternative fallback to EUV isn’t much better: quadruple patterning on heaven knows how many mask layers. In either case, you’ll be able to calculate wafer outs on an abacus.
Let’s wrap things up:
- The CapEx required to bring up 7nm will be off chart—even if we use a log scale—if not in the form of 50 metric ton (seriously) EUV gear, then in the form of the army of conventional steppers needed to keep up with the quadruple patterning.
- The number of customers that will be able to afford 7nm may prove to be non-zero, but you won’t need an abacus to count them. The digits on one hand will do just fine, heck, you’ll likely have spares for ECC.
Now THAT certainly sounds … tumbleweeds … crickets … like the music stopping.


