


As usual, my mind is buzzing with hitherto unthought thoughts. The topic du jour is emotion-aware conversational AI that combines speech recognition with paralinguistic understanding. Ha! I thought that would get your attention and give your excitement juices a bit of a stir.
It’s not so long ago that the ability to communicate with tools like smart assistants and say things like “Alexa, turn on the living room lights” using natural language commands would have seemed like something out of a science fiction movie. Of course, the writers of the movie script would have envisaged a scene something like the following:
Human: “Alexa, turn on the living room lights.”
Action: Living room lights turn on.
Meanwhile, back in the real world (we hope you’ll enjoy your stay), what actually happens at our house is more along the following lines:
Human: “Alexa, turn on the living room lights.”
Alexa: “There are multiple lights… which ones do you want?”
Human: “The living room lights.”
Alexa: “Do you mean the breakfast room lights?”
Human: “No, the living room lights.”
Alexa: “Do you mean the bedroom lights?”
Human: “NO! THE &^^&%^% LIVING ROOM LIGHTS %^$%%^%”
Action: Some lights somewhere in the house turn on (if you’re lucky, otherwise the garage door opens).
To be honest, things really aren’t as bad as I’ve portrayed them here, but there have been occasions where it’s been a close call. Much of the problem lies in the classic speech recognition pipeline, which remains the default. This starts with wake-word detection, which runs locally on the smart device. Next, your audio command is transmitted to the cloud, where it undergoes automatic speech recognition (ASR). This is where your spoken command is converted into text (i.e., speech-to-text). It’s this text that’s fed into the natural language processing (NLP) stage, which is used to interpret its meaning. Eventually, this results in an action/response, such as turning on the wrong lights.
The problem with traditional systems is that they mostly ignore emotional nuance, focusing on words and intent rather than how you sound. The term “paralinguistic” refers to everything in speech other than the actual words; that is, the way something is said rather than what is said. Newer systems are beginning to analyze paralinguistic features in audio, including tone, pitch, speaking rate, pauses, and stress (prosodic, not emotional). This allows them to detect emotions such as excitement, frustration, anger, and urgency.
Let’s take a step back. I think it’s fair to say that when we (human beings) wish to communicate with each other, voice is our native medium. We have other mechanisms available to us, of course, like sending a text message. However, when speaking, we convey a lot of meaning through tone, inflection, cadence, timing (including pauses and pregnant silences*), and emphasis—none of which can be fully captured in text alone. (*My wife, Gina the Gorgeous, can deliver a pregnant silence that leaves my ears ringing.)
Consider the following example. You’re a little late to an event when you receive a text from a friend saying, “Hey, are you coming?” Are they just checking in? Are they worried about your safety? Are they acting passive-aggressive? Are they frustrated that you’re not there yet? It’s very hard to tell from the text alone. By comparison, if they called you with the same query, you’d have a much better idea as to where they were coming from (emotionally speaking) and how best to respond.
Another aspect of this is that when you’re talking to a smart assistant like Amazon Alexa, you regulate yourself and end up speaking very differently than you would to a human. We’re so worried that our AIs won’t understand us that we hold ourselves back, simplifying the way we speak and limiting our vocabulary and expression (unless we get cross, at which point all bets are off on the expression front).
As another example, consider a study conducted in the contact center space (a centralized operation where a company handles all its customer interactions). In this study, they examined what happens when an AI or a human on an outbound sales call asks a potential customer, “Do you own your home?” If it’s an AI asking the question (assuming the customer knows it’s an AI), they will typically respond in one of only five ways: “Yes,” “No,” “I have a mortgage,” and so on. By comparison, if the customer knows they are talking to a human, there are hundreds of different ways in which they may respond, including things like, “Well, the bank hasn’t repossessed it yet… ha ha ha.”
The bottom line is that there’s a lot of character and humor we feel comfortable expressing with other humans that enrich our interactions, which we are unwilling to communicate in conversations with AIs because we don’t expect them to understand it.
In the best of all worlds, when we are trying to have a conversation with an AI, we should be able to treat the AI like we would treat a human. We shouldn’t have to regulate ourselves or learn a new skill to talk to the AI. The AI should learn how to talk to us in a way that’s native to us and feels comfortable and familiar.
The reason I’m waffling on about all this is that I was just chatting with Mike Pappas, who is CEO and Co-Founder of Modulate, which is proud to proclaim itself: “The world’s leader in conversational intelligence, especially when it comes to dynamic, emotive, noisy, and downright messy conversations as are the norm in the real world.”
As an aside, Mike’s co-founder and Modulate’s CTO is Carter Huffman. This dynamic duo looks like a pair of characters plucked from an episode of The Big Bang Theory. In fact, they met when Mike cracked a physics problem that Carter was whiteboarding in a hallway at MIT.

Mike (left) and Carter (right)
Just saying this, of course, reminded me of the time when Leslie fixed the equation on Sheldon’s whiteboard.. I love the bit at the end when Sheldon says, “I don’t come into your house and touch your board.” And Leslie replies, “There are no incorrect equations on my board.”
I’m still laughing, but we digress… Mike introduced me to Velma. This is Modulate’s voice intelligence platform, powered by their Ensemble Listening Model (ELM). Rather than flattening conversations into text transcripts, Velma analyzes speech as a multi-dimensional signal—combining words with tone, timing, emotion, and behavioral cues. By orchestrating hundreds of specialized models working together in real time, it builds a rich, evolving understanding of each conversation—what’s being said, how it’s being said, and what it actually means.
A high-level view of the Ensemble Listening Model is shown below. At first glance, you might think this is just another speech-to-text pipeline with a bit of extra seasoning sprinkled on top. It isn’t. Instead of flattening audio into a single stream of words, the ELM explodes each conversation into a rich tapestry of parallel signals—emotion, timing, intent, behavior—all processed by swarms of specialized models working in concert. These signals are then woven back together by an orchestration layer that builds an evolving understanding of what’s really going on: not just what was said, but what was meant.
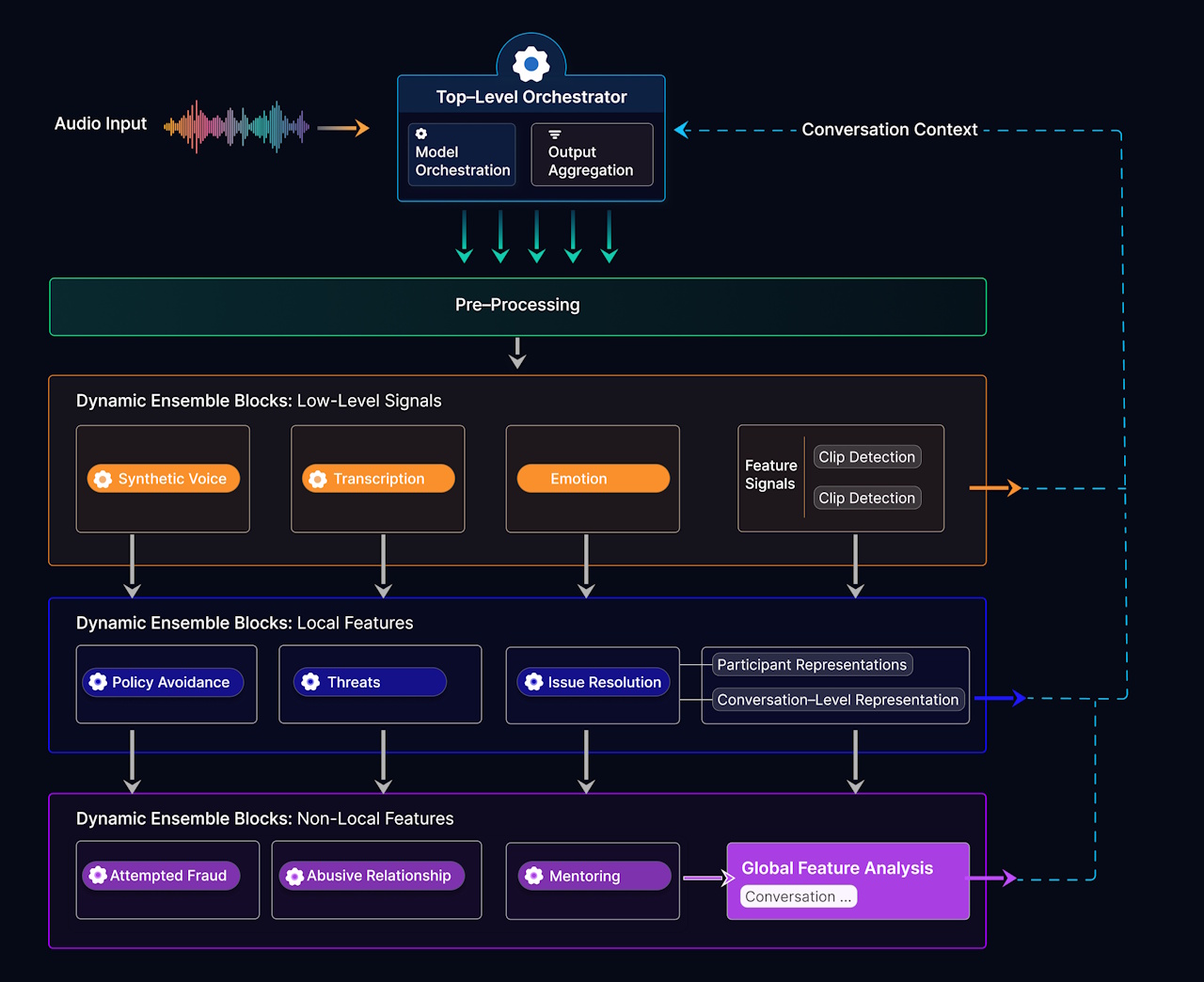
But here’s the thing: architectures are only half the story. The other half—the part that often matters even more—is the data. It’s easy to say, “data is king,” but in the world of voice AI, that kingdom is surprisingly hard to build. Many companies developing speech systems are forced to construct their own datasets from scratch. Some rely heavily on synthetic data, such as AI-generated voices speaking carefully curated phrases under relatively clean conditions. That can take you a long way when your goal is transcription, but not so far when your goal is understanding.
The problem is that real human conversations are messy. They overlap. They interrupt. They wander off-topic (have you met my mother?). People mumble, shout, whisper, laugh, and talk over background noise. They use sarcasm, humor, understatement, exaggeration, and cultural shorthand. And—perhaps most importantly—they say things they don’t literally mean. For example, if you overheard someone say “I hate you!”, you could easily take this the wrong way if you were unaware that the other person in the conversation was a close friend who had just announced, “I snagged this awesome T-shirt for just $5!”
This is where Modulate’s origin story becomes rather interesting. They didn’t start in a quiet lab with pristine recordings. Instead, they started in the gaming world—monitoring real-time voice chat in titles like Call of Duty and Grand Theft Auto. In that environment, the challenge isn’t just to recognize words, but to understand intent. Is this genuine hostility, or just a bunch of friends gleefully trash-talking each other? The difference can be subtle, but the consequences of getting it wrong can be significant.
Over time, this gave the chaps and chapesses at Modulate something incredibly valuable: not just a clever architecture, but a vast corpus of real-world conversational data—hundreds of millions of hours of it—capturing people talking in all their chaotic, energetic, emotionally expressive glory. That’s the sort of training ground that teaches a system how to handle background noise, emotional nuance, and the delightful unpredictability of human speech.
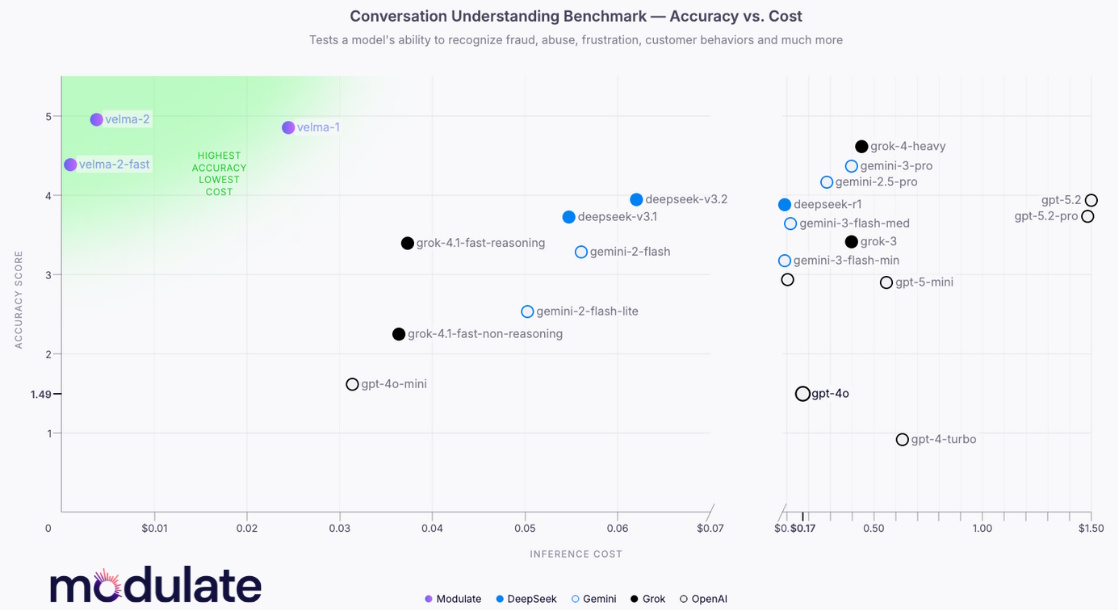
As a result of all this, as illustrated below, Velma outperforms all other competitors in an industry-standard conversational understanding benchmark. Even better, it does this at a fraction of the cost of its competitors.
In turn, Velma’s high accuracy and low cost open the door to a wide range of applications. On their website, the folks at Modulate highlight several ways in which this kind of voice intelligence can be put to work:
- Enrich Customer Experience: Improve quality, reduce attrition, and protect the customer experience.
- Power Voice Conversations: Give human or AI agents a set of digital ears that catch hidden meaning, cultural context, and emotional state.
- Fight Fraud and Scams: Detect social engineering, coordinated attacks, and deepfake-driven manipulation before damage is done.
- Evaluate and Guardrail AI Voice Agents: Monitor your own AI agents just as you would human ones, flagging risky interactions and maintaining trust at scale.
- Bolster Community Safety: Leverage technology forged in real-time multiplayer environments to identify abuse, anger, and harmful behavior, even when it’s wrapped in humor, slang, or context-dependent banter.
A natural home for many of these capabilities is the contact center, which is the front line where companies interact with their customers in real time. In this environment, understanding what a caller says is important. Understanding how they say it can be critical. Is the customer mildly annoyed, deeply frustrated, or on the verge of churning? Is the caller who sounds perfectly polite actually attempting a social engineering attack? These are the kinds of signals that can be easy for humans to miss—especially at scale—but that a system like Velma can flag in real time.
And it’s not just about augmenting machines—it’s about augmenting people. For example, I spend a fair amount of my time on video calls. It’s not hard to imagine a future in which a little unobtrusive overlay tells me that one participant is amused, another is confused, and a third is quietly getting irritated with my ramblings (surely not!). In cross-cultural conversations or large-group discussions, that kind of real-time emotional context could be surprisingly powerful, helping people to respond more appropriately, build rapport more quickly, and avoid accidental misunderstandings.
But wait, there’s more! The guys and gals at Modulate have started breaking out individual components of their Ensemble Listening Model and offering them as standalone capabilities. Instead of having to consume the entire Velma platform, developers can now tap into specific “dynamic ensemble blocks”—each one effectively a “mini-ensemble” in its own right—targeted at particular tasks.
The first of these to emerge was Velma Transcribe. At first blush, you might think, “Ah, transcription—we’ve had that for years.” But this isn’t your grandfather’s speech-to-text. Built using the same ensemble philosophy, Velma Transcribe orchestrates multiple specialized models to handle the messy realities of real-world conversations—overlapping speakers, accents, interruptions, and background noise. The result is not only higher accuracy on conversational audio but also dramatically improved economics, with costs on the order of a few cents per hour, which is an order of magnitude lower than many existing solutions. In effect, this makes large-scale transcription not just possible, but both affordable and practical.
![]()
Results from transcription understanding benchmark (Source: Modulate)
Hot on its heels comes Velma Deepfake Detect—and this is where things start to get a bit exciting (and, depending on your disposition, slightly alarming). Rather than sampling a few seconds of audio and making a best guess (as many systems do), Modulate’s approach enables continuous monitoring throughout an entire conversation.
Thanks to the efficiency of their ensemble architecture, they can analyze every moment of a call at a cost that’s not just competitive but, in some cases, over 100× lower than traditional techniques. This changes the game entirely. Instead of leaving gaps that a savvy fraudster can exploit, the system is effectively “always listening,” spotting synthetic voices even in noisy, real-world conditions—the very conditions it was trained on in its gaming days. The end result is a shift from occasional verification to persistent vigilance, which is exactly what’s needed as deepfake-driven fraud continues its upward trajectory.
I have to say, I find all this extremely exciting. Having said this, I also find myself sitting squarely on the horns of a dilemma (which is not as comfortable as one might hope). Thinking about the previously mentioned video call scenario, for example, it would be rather splendid to know what the other participants are thinking—who’s amused, who’s confused, and who’s quietly wondering why I’m still talking. But then, of course, they would know exactly the same things about me. There’s also a fine line between “helpful insight” and “I now know far more than I’m entirely comfortable knowing.”
There’s an even bigger question lurking in the background. For thousands of years, we humans have relied on subtle cues—tone, timing, hesitation, emphasis—to read between the lines. These signals are powerful precisely because they are fleeting and subjective. Now we are on the verge of turning them into something measurable, persistent, and, dare I say, quantifiable. That’s both fascinating and faintly disconcerting in equal measure.
On the other hand—as anyone who’s spent time with me will attest—I tend to adopt a “be happy, don’t worry” attitude and go with the flow. Technologies come, technologies go, and we humans have an uncanny knack for adapting to them (usually while grumbling a bit along the way). As these systems continue to evolve, the idea of giving both humans and machines a better set of ears—ears that can hear between the words—feels less like science fiction and more like an inevitable next step.
And who knows? Perhaps one day, when I’m on a call and my virtual assistant quietly informs me that everyone is thoroughly enjoying my ramblings, I’ll probably choose to believe it… even if it’s only telling me what it thinks I want to hear.

