

Once again, my world has been turned upside down. Until recently, I’ve been gasping in awe at the myriad “you won’t believe your eyes” numbers flaunted by proponents of the latest and greatest GPUs, like Nvidia’s H200, which boasts nearly four petaflops of AI compute… at least, on paper. So, you can only imagine my surprise to discover that these high-end GPUs can be outperformed by FPGAs. As I said in the title of this column: “Say What?!?” (I only hope the persnickety punctuation police perceive that this doesn’t technically end with an exclamation mark.)
As an aside, I find it amusing to recall that I was there when FPGAs appeared on the scene in the mid-1980s. The first devices had 8 x 8 = 64 configurable logic cells and no design tools to talk about. “They’ll never catch on,” I said to myself, thereby demonstrating my embarrassing lack of prophetic prowess, but we digress…
These days, I’m a huge fan of FPGAs (I’m famous for it), constantly bragging about how CPUs are inherently sequential and inefficient, while FPGAs can execute algorithms with extreme efficiency in a massively parallel fashion. Of course, GPUs can also execute algorithms in a massively parallel fashion (they’re famous for it), so what gives?
Another consideration is that if you want to achieve the highest performance while consuming the lowest power, a custom ASIC is generally considered to be the way to go. And, of course, we could say that a GPU is essentially a custom ASIC, although we should probably qualify this by saying something like, “A GPU is a programmable, general-purpose ASIC optimized for parallel compute, and not a fixed-function ASIC” (I tell you, that course I took on “How to Use Weasel Words” is really paying dividends).
But… and there’s always a but… when we’re talking about custom silicon for AI, like GPUs, it behooves us to note that these devices are built to be as general-purpose as possible. For example, GPUs are designed to handle AI training workloads, AI (ML) inference workloads, high-performance computing (HPC) workloads, and… well, graphics workloads, I suppose. (Their applicability to cryptocurrency mining is a by-product, not a design goal.)
The point here is that the more general-purpose something is, the more its efficiency is typically degraded for specific tasks. Even within a subset like inference for large language models (LLMs), each model may be best served by a specific architecture, but general-purpose GPUs must, by definition, serve multiple LLMs, meaning each type of LLM is not served as well as one might hope.
All this is at the core of why FPGAs can dramatically outperform GPUs for LLM inference: they can be reconfigured on an LLM-by-LLM basis to provide the optimal solution. Another aspect of this is that the AI space is extremely fluid at the moment. For example, it wasn’t so long ago that transformers appeared on the scene. This was followed a couple of years later (it takes time to design and build a silicon chip) by custom silicon whose owners proudly proclaimed could natively handle transformers.
But then the Mixture of Experts (MoE) concept came along. This is a way to build neural networks—especially LLMs—so that only part of the model is used for each task, rather than the whole model every time. The basic idea behind MoE is simple. Instead of one giant “brain” doing everything, you have lots of smaller specialist brains—called “experts”—and a router that decides which ones to use for each input. Only a few experts are activated for any given request.
Traditional transformer models use all their parameters for every token, resulting in a predictable but dense compute load. By contrast, MoE models use only a subset of parameters per token, leading to sparse, much more dynamic computation. For example, a model might have 100 experts, but each token uses only 2 of them, so the total parameter count is huge while the compute per step is much smaller.
In short, Mixture of Experts means many specialist subnetworks with only a few active at a time, which is great for scaling AI, but problematic if your hardware assumes “everything runs everywhere all at once,” as it were. The great thing about FPGAs is that they can be reconfigured to address new concepts, like MoE, almost as soon as they come online.
The reason I’m waffling about all this here is that I was just chatting with Mohammad Rastegari (CEO), Saman Naderiparizi (CTO), and Mahyar Najibi (CSO) at ElastixAI. As the company’s moniker suggests, the chaps and chapesses at Elastix have developed an “elastic” FPGA-based solution for the AI inference problem. This solution is FPGA- agnostic, supporting devices from Altera, AMD, and Achronix.
One thing I really appreciated about our conversation is that—unlike many
presentations I’ve fought my way through—Mohammad, Saman, and Mahyar didn’t attempt to bury me under a mountain of PowerPoint slides. Rather refreshingly, their presentation contained only three graphics for me to wrap my brain around (other companies could take lessons). They started by providing me with a high-level overview of the problem and their solution as follows:
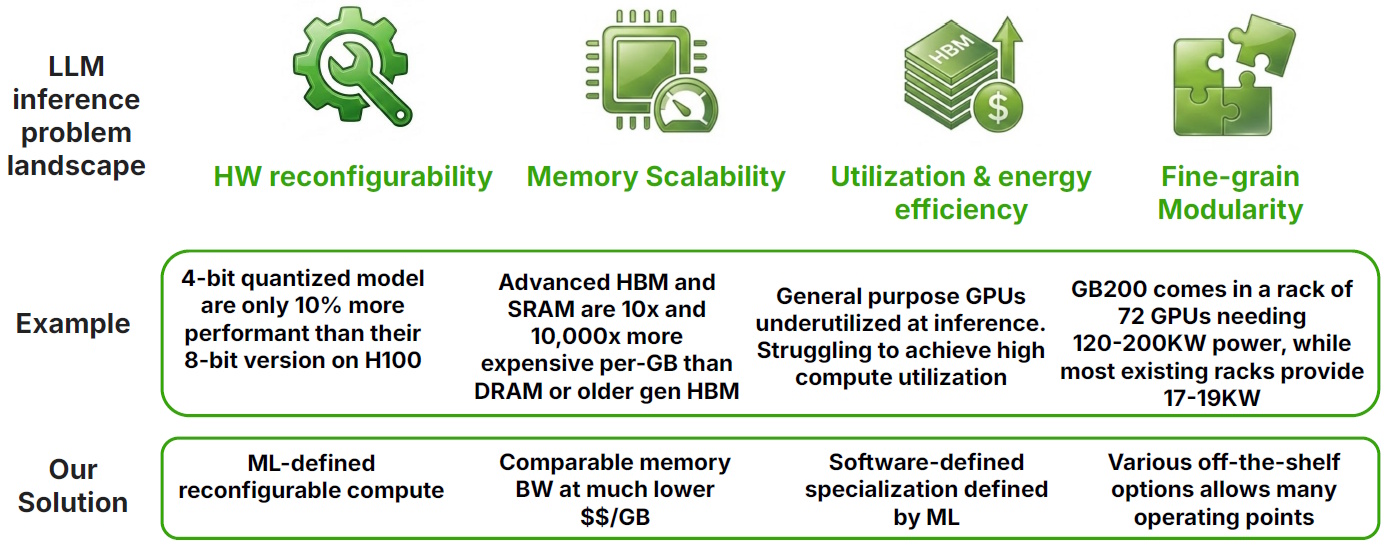
The LLM inference problem landscape (Source: ElastixAI)
This highlights how today’s LLM inference landscape is being squeezed from multiple directions. First, there’s the issue of hardware reconfigurability (or, more accurately, the lack thereof). Custom silicon at the level of today’s high-end GPUs takes three to five years from architectural definition to deployment. In AI terms, this is “a lifetime” during which the underlying models can change fundamentally.
Second, there’s memory scalability. High-end solutions rely on the latest HBM and SRAM technologies, but these can be 10× to 10,000× more expensive per gigabyte than alternatives like DRAM or older-generation HBM, even though inference workloads don’t necessarily require the bleeding edge to achieve the bandwidth required.
Third, we have utilization and energy efficiency. Modern GPUs are designed to handle everything from training to inference to graphics, but this generality comes at a cost. During inference, which is typically memory-bound, much of the available compute goes underutilized, while power requirements continue to climb (think racks consuming on the order of 120 to 200 kilowatts).
Finally, there’s the question of fine-grain modularity. Today’s solutions tend toward large, monolithic, rack-scale deployments, which makes it difficult to “slice and dice” compute to match real-world constraints, such as fitting a meaningful inference capability into a few kilowatts in an existing data center. Taken together, these challenges help explain why a more flexible, ML-defined, and reconfigurable approach—such as that offered by FPGAs—starts to look very attractive indeed.

A tale of two racks (Source: ElastixAI)
Elastix’s answer to all of this is to flip the problem on its head by making the hardware adapt to the model, rather than the other way around. In place of rigid, fixed architectures, they employ ML-defined reconfigurable compute, in which the FPGA is configured to implement only the primitives required by a specific model and can be reconfigured as that model evolves, thereby eliminating the multi-year lag associated with custom silicon.
On the memory front, their approach delivers comparable bandwidth at a much lower cost per gigabyte by leveraging more flexible memory choices, such as DRAM or earlier-generation HBM, rather than being locked into the latest—and most expensive—technologies.
With respect to utilization and energy efficiency, the idea is to create a software-defined specialization that tightly maps the workload to the hardware, thereby avoiding the underutilization seen in general-purpose GPUs and improving overall inference efficiency.
Finally, their emphasis on fine-grain modularity allows systems to be constructed from various off-the-shelf FPGA options, supporting a wide range of operating points—from large-scale data center deployments down to much smaller, power-constrained environments—so users can scale up or down as needed, rather than being forced into a one-size-fits-all rack-scale solution.
Of course, none of this would matter if adopting the technology required ripping out your existing infrastructure and starting from scratch. This is where Elastix’s “frictionless drop-in replacement” story comes into play, as illustrated below.
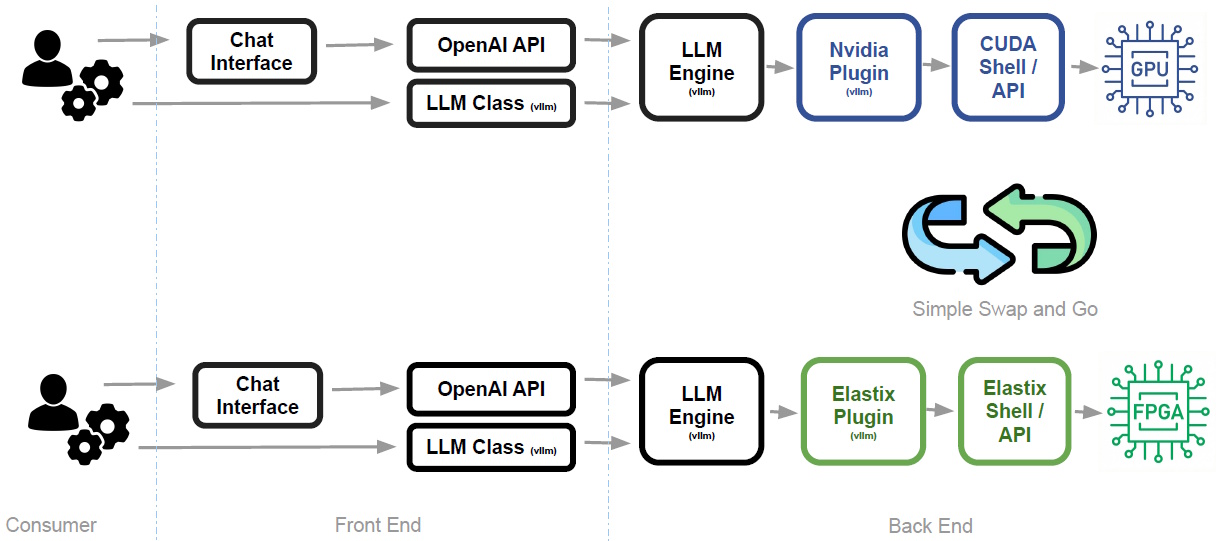
Elastix offers frictionless drop-in replacement (Source: ElastixAI)
The Elastix solution sits neatly within the existing software stack, supporting familiar interfaces like the OpenAI API and frameworks such as vLLM, but swapping out the underlying NVIDIA/CUDA layer for an Elastix plugin and runtime.
The net result is what the guys and gals at Elastix describe as a “simple swap and go experience.” From the consumer/user’s perspective, the front end and application logic remain unchanged, while the back end transparently transitions from GPU-based execution to FPGA-based acceleration. In other words, you keep your existing workflows, tools, and APIs while gaining the benefits of a more efficient, reconfigurable inference engine without any of the usual integration headaches.
So, are FPGAs about to dethrone GPUs for LLM inference? Probably not overnight. It’s fair to say that GPUs aren’t going anywhere anytime soon. They remain astonishingly powerful, incredibly well-supported, and deeply embedded in the AI ecosystem (and you can quote me on that).
But the real story here isn’t about one technology replacing another outright; it’s about a shift from rigid, one-size-fits-all compute to something far more fluid and adaptable. As AI models, algorithms, and architectures continue to evolve at breakneck speed, the ability to reshape the hardware to match the workload—rather than forcing the workload to fit the hardware—could prove a decisive advantage. GPUs may rule the roost today, but in an AI world that refuses to sit still and behave, “elastic” architectures like this might be the ones best equipped to keep up with tomorrow.

