


Voice is a hot topic these days. It represents the layering of a lot of technologies, from identifying and separating sounds to identifying individual voices to identifying specific words. And, while voice recognition is a broad topic, specific applications are effectively being layered above it for so-called “smart speakers” – the Alexas and Dots of the world. And right away, I’m going to warn you that we’re likely to get confused since speakers (human) are talking to speakers (“smart”). Hang on tight.
Let’s be clear: full voice processing takes a lot of work. If one of these devices is going to be completely self-sufficient, it’s going to be expensive. So the challenge is to do a minimal amount of work in the speaker and then do the rest in the cloud. XMOS refers to this as maintaining a thin client.
So our focus for today is on two development boards that target smart speakers: Eval kits for VocalFusion Circular and Linear from XMOS and a Voice Capture Development Kit from Cirrus Logic.
Fusing – or unfusing – voices
All the boards feature multiple microphones – up to six for XMOS (arranged circularly or linearly; circular version shown below) and two for Cirrus Logic. In the XMOS reference design, however, up to four are used, arranged linearly or in a rectangle on their custom boards. Connectivity is via USB 2.0 or I2S.

(Image courtesy XMOS)
Cirrus Logic uses a Raspberry Pi 3 board with a separate card that can be stacked or attached by ribbon cable. USB is available for a keyboard and mouse, but this can also be run in a “headless” mode by using the wireless connection and driving it from a browser. The kit includes a passive speaker, but there’s also a signal-out port for use with powered speakers. The audio board features their own MEMS mics and processing chip.

(Image courtesy Cirrus Logic)
The challenge for anyone taking on this application is to identify a speaker – of the human kind – that utters a command. There could be multiple people talking in the room; the room itself could be acoustically messy; there could be lots of background noise; and, critically, the smart speaker (which is also listening) could be playing music or talking at the same time as someone is issuing a new command.
So, to start with, lots of clean-up is required to eliminate noise. Then there’s the beam-forming thing: with multiple mics, you can “point” the collective set of mics in a direction to, literally, focus on a specific source of sound (preferably a human). XMOS decides which direction to point based on the loudest voice – not in any one mic, but overall. If the speaker changes to someone else in a different position, they can refocus in milliseconds in any direction.
XMOS’s processing is summarized in the following diagram:
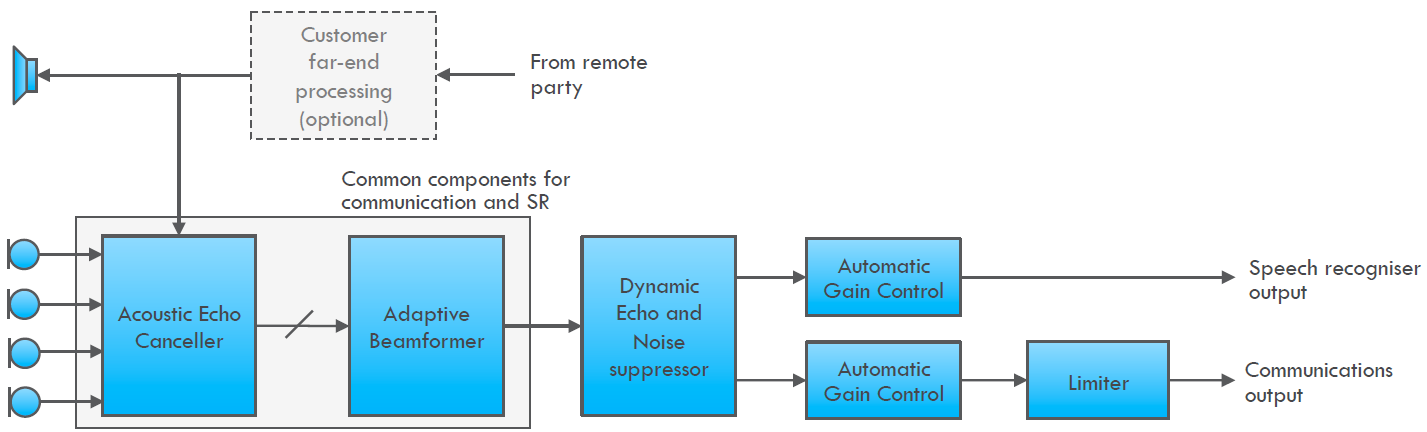 (Click to enlarge; Image courtesy XMOS)
(Click to enlarge; Image courtesy XMOS)
Cirrus Logic has a similar block diagram, with its own variations:
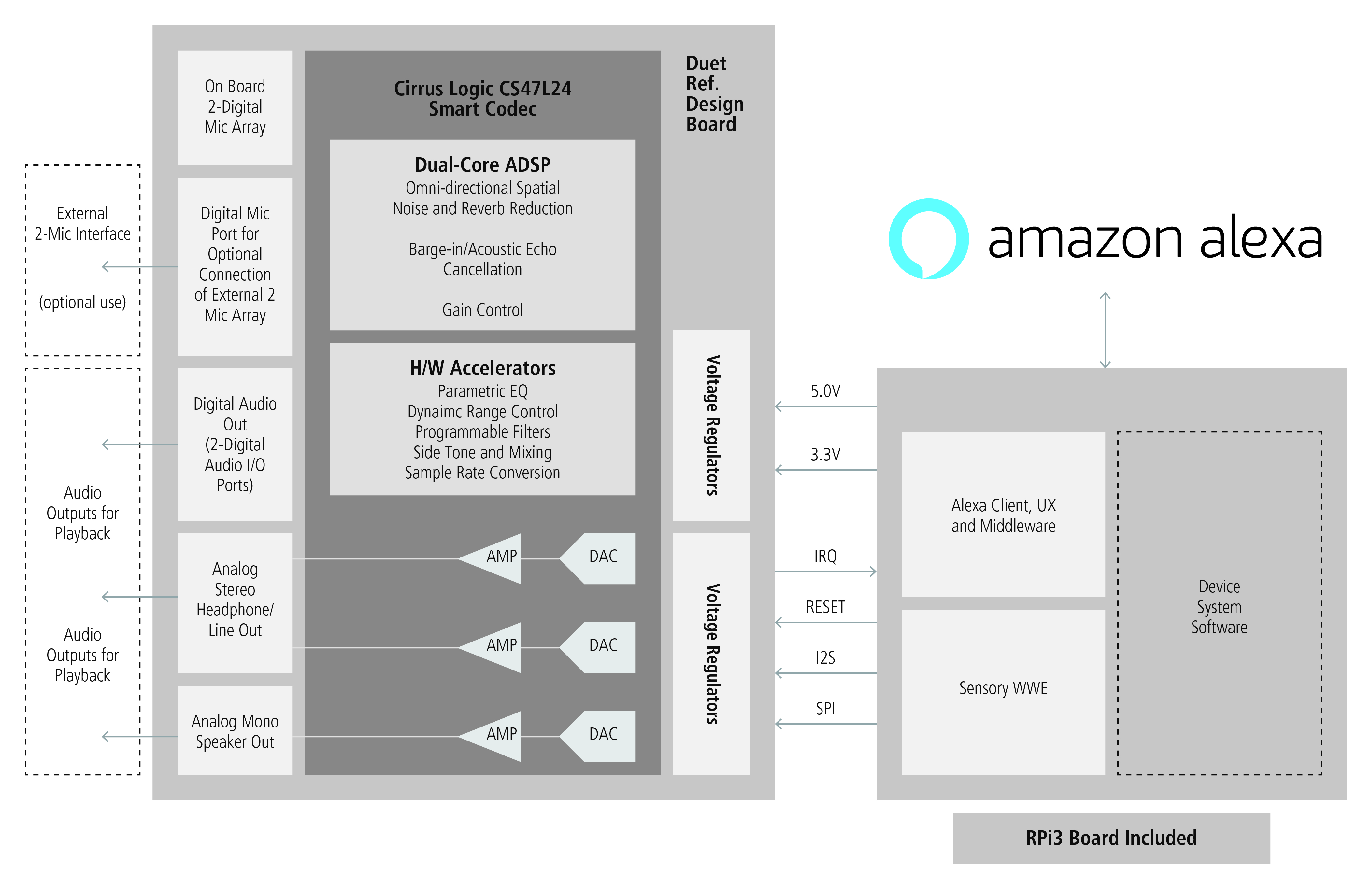 (Click to enlarge; image courtesy Cirrus Logic)
(Click to enlarge; image courtesy Cirrus Logic)
The echo cancellation is particularly important for that last acoustic challenge: talking to the smart speaker when it’s talking or otherwise issuing sounds (as speakers of the stereo sort are wont to do). This feature has a colorful name: barge-in. “Yeah, Alexa, I’m going to let you finish, but I have something I want to say without waiting.” So the speaker has to be able to isolate the incoming new command from the sounds it’s playing.
Both companies appear to have engaged Sensory for the job of actual command interpretation.
XMOS is focused enough on voice applications that they’ve created a new brand: VocalFusion. They find their platform to be particularly well suited for thin-client voice applications. And it’s important to distinguish their processing chips from the applications they’re bundling with them. The chips are the XVF3000 and XVF310x platforms; the application is VocalFusion Speaker. Both chips appear to be able to handle the app, although the XVF310x chip is needed to include the Sensory keyword recognition feature.
The pre-canned software for the rectangular and linear configurations comes locked with a key that binds the code to the chip.
The Cirrus Logic solution comes with a MicroSD card containing object code that will spin up immediately. Reference source code is available, however, on Amazon’s Github; they also provide reference driver code to help with implementations either on other Raspberry Pi boards or with other SoCs.
It’s a Cocktail Party
In separate but related news, XMOS also acquired an audio company called Setem, with whom they’d already been working. They provide low-level algorithms that attempt to solve the “cocktail party effect” problem: picking out a single voice from a soundscape that includes a mix of voices and other sounds.
They can create a 3D map of the sound with 3 (presumably appropriately placed) mics, and you can then see a “heat map” of the soundscape. They identify fundamental and harmonic frequencies by using high-resolution frequency buckets – in the tenths of Hz, operating on frames of 64 ms. Prior solutions apparently had trouble with aliasing at bucket boundaries; with such fine gradations, this is less of an issue. They also use proprietary math for their time/frequency analysis, which they claim also gives them an advantage.
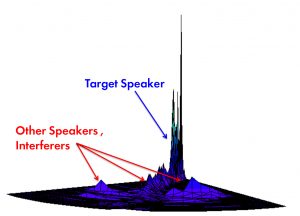
(Image courtesy XMOS/Setem)
This made me wonder how well it could dissect music. If you have one voice singing, then it’s… well, I don’t know if “easy” is the right word, but perhaps more straightforward to identify the voice and its frequency components. But what if you have a barbershop quartet going? Heck, if they do a good enough job, you’ll have four voices but even more “notes,” based on shared reinforced overtones.
In a discussion with them, they said that they can pull apart harmony. Thinking through it, if you can identify the location of each singer, then that helps – because if vocal lines cross, then the higher note might pass from one singer to another. You could presumably keep track of who has what line by correlating with their physical position – but if they move and exchange positions? Another critical piece is the fact that each voice has a characteristic spectrum. When they see a fundamental move and then a series of stacked overtones moving in synchrony, they can cluster those together and assign them to a specific singer.
It’s not clear to me what the killer app is for pulling Sweet Adeline apart, but it’s certainly an example of a non-trivial task. And, even though they could, XMOS/Setem aren’t planning to dive into the professional audio world.
No products have yet been announced based on this new marriage. They’re working feverishly to meld the technologies, creating new dedicated instructions, for example, for improving performance.
More info:
XMOS xCORE VocalFusion Speaker




What do you think of XMOS’s and Cirrus Logic’s smart-speaker dev kits?