


At the beginning of this year, we looked at a new company that was attacking the whole issue of creating efficient multicore code that works identically to a single-core version. If you haven’t involved yourself in that, it might seem simple – but it’s anything but.
The company was – and still is – Silexica. And, like everyone else that’s tried to plow this field, they continue to learn about the best ways to integrate their technology into embedded flows – particularly with respect to automotive designs. I had a recent conversation with them and learned of a number of changes to how they approach multicore embedded systems.
The Incumbent Flow
The high-level idea is to take programs and implement them on any kind of multicore architecture in a way that’s correct-by-construction and efficient, where efficiency is focused primarily on performance but can also help optimize power. Early flows have accomplished this as follows:
- Start with a pure sequential version (probably C or C++) of the program.
- Analyze that program on a host computer to figure out the good and bad places to split the program into parallel threads.
- Present the target system architecture and let the user map different threads onto different computing engines.
- Have the code generator create the appropriate code for each computing engine. The collection of threads will be guaranteed to work the same as the original code. (If you don’t follow the flow, that might not be the case.)
Sounds straightforward, but there are some challenges here:
- Not everyone starts with pure sequential code. There may be a mix of code sources, and some of them may already be parallel. But, just because they’re already parallel doesn’t mean that they’re as efficient as they could be, so you may want to re-optimize.
- There are many alternatives to C as inputs, especially if you’re bringing in pre-parallelized code. Variants include in-line assembly code, Pthreads, C++ threads, OpenMP, and AutoSAR.
- If you can analyze only on a host computer, then you can’t work with a program that has in-line assembly.
There turned out to be some additional marketing challenges. The old messaging focused on the literal tools being used – analyzing, mapping, and generating code. But, depending on the application and the source of code, there were variations to this, and, evidently, it got confusing.
A New Remix
So they made a number of changes. We’ll start with the marketing message, but, to be clear, the changes aren’t just the same old technology rewrapped in new, shinier paper. And, in fact, the new message sounds very similar, to my ear, to the old messaging – but, apparently, it’s making a difference.
The three steps now put forth replace analyze/map/generate with analyze/optimize/implement. What seems to work better here is that “optimize” and “implement” abstract away the flow variations that accompanied “map” and “generate,” making for a simpler story.
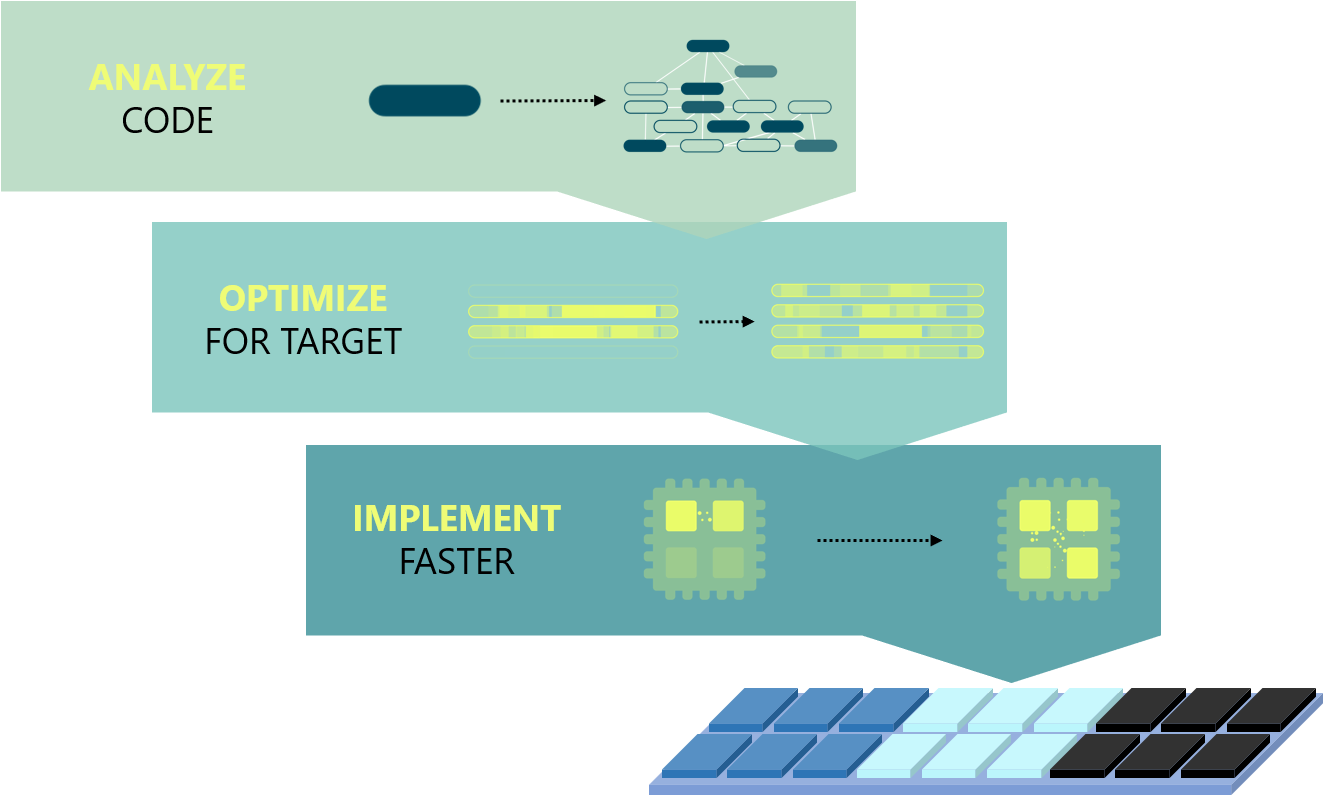
(Image courtesy Silexica)
As a named step, “analyze” might look not to have changed, but there are a number of key changes that significantly broaden the range of programs that can be analyzed.
Probably one of the biggest changes is the ability to analyze programs that have already been parallelized – either well or poorly. The idea is that, in the absence of automation tools, parallelization must be done by gut. Yes, there may be some major pieces that you know, based on how the program works, can be split up and run in parallel. But, without actual data, you simply won’t know whether you’ve done the best possible job. In the worst case, you may have missed some data dependency such that, in a corner case that escaped testing, the program may not operate correctly.
So feeding those pre-parallelized programs into analysis can give you that needed data. There’s a chance that you’ll run it and pat yourself on the back, having found no improvements. Chances are not, however.
Analyzing a parallel program means broadening the range of inputs that can be accepted. At a high level, they can take in data flow specs and process networks. They’ve added Pthreads, C++ threads, and OpenMP version 4.5 to their list. In addition, a focus on automotive applications, which reflect a different culture as embodied in AutoSAR (what with all the global variables and “runnables” instead of “functions”) means that the tool can take in code originating from AutoSAR – including AutoSAR specs.
This supports a general move from automotive code running on a single core to three, or as many as six, cores.
Another improvement allows analysis of programs with in-line assembly code. I’m not privy to all the details of how analysis is managed, but one long-standing element of it can involve analysis of load/store patterns. The program is instrumented such that loads and stores are recorded. Analysis of the resulting patterns can give important information about which variables are dependent on which other variables at any given time.
Given a pure C program, for instance, this can readily be implemented on a host computer that bears no resemblance to the embedded system for which the program is eventually intended. Loads and stores will occur on the host just as they would on a device. But if your program has some in-line assembly, you won’t be able to run it on the host (unless, by some inconceivable* quirk, the host runs the same processor – or a close relative – of the one in the target device). For this reason, they now allow analysis to be run on the target processor(s) rather than on a host.
After analysis come optimization and implementation. These are new tools, although some elements of the old tools were brought over. While optimization focuses on performance, you can also obtain average and peak power estimates. Complementing the broader range of input formats are a broader range of outputs, including automatic insertion of parallelization pragmas in a variety of formats as well as AutoSAR support.
To Cloud or Not to Cloud
Finally, we come to the deployment model. Back when I was personally involved in this technology (I can’t believe it’s already been ten years! Timing!), we started with a cloud implementation. After I was no longer involved, the usual cloud bugaboo became evident: getting engineers to send critical code into the cloud is a tough row to hoe. So that company moved away from the cloud.
In the present, Silexica CEO and co-founder Max Odendahl commented that he has always taken a “never will this ever be in the cloud” stance – and yet he’s moderating that position now. They’ve provisioned the tool for the cloud, but they haven’t lost sight of what makes the cloud problematic.
They envision a typical public cloud implementation, but this will be for evaluation purposes only. They say that they have plenty of prospects that want to do a test drive, but they’ll run that test with innocuous (relatively) code. This capability has been available for a few months, and they expect that, by the time this is printed, they’ll have had around 120 such evals (the number to date, when they told me this, was already over 100). But, to be clear, that’s not 120 actual customers doing real projects in the cloud; they’re all test drives.
For companies that have internal private clouds, however, the tools can be rolled out in a cloud configuration for production use, since the critical code will never leave the company. In this mode, you can insert analysis into the check-in flow and run nightly regressions on new code to confirm that nothing is breaking as existing code changes.
So, with these changes, we’ll see whether this technology can enter mainstream design. Or whether yet more changes are needed.
*I don’t use that word often, but I’m pretty sure it means what I think it means.
More info:




What do you think of Silexica’s newer approach to software parallelization?
Having done my PhD thesis on exactly this problem for cloud/cluster based systems, the answer is — It depends. The majority of any given code analysis is what are you optimizing for? Parallel operation is not always the answer. Consider the classic “Towers of Hanoi” where frame context (recursion) is relied on to solve the problem. Parallel operation would be useless for that algorithm. Thus it is algorithm decomposition that is required. Consider the Berkley Dwarfs and van der Aalst workflow patterns. If the workflow can be broken into identifiable work packages, these can be scheduled (i.e. mapped) to individual processors. And then the data on which the algorithm operates has to be partitioned as well. Silexica may be good for some workflows, but not universally.
I’ve lived through the Convex, CRAY, Nvidia, Convey (see Convex), FPGA (various flavors), and the Intel MIC accelerators and each one DEPENDS on the algorithm that you try to fit to it. Ipso facto, no universal decomposition. This is where my thesis differed from the common though. First you figure-out the algorithm, and then fit it to the correct processing element. Embarrassingly parallel is easy to map. Many non-fluid dynamic scientific codes are not easy to decompose. General processing is a case by case basis. Since it takes time to do the correct decomposition, only high pay-off algorithms are considered (i.e. machine-learning for commercial trading floor).