


Ah, the air has cooled. The sun lolls about at a low angle for a few tentative hours. Morning frosts seal the fate of any remaining tender plants. Here in northern Oregon, the Gorge winds blow random gale-force patterns, making it unnecessary to sweep the leaves off of the patio. And, slightly farther north, it’s ITC (that would be the International Test Conference) season, in Seattle this year.
Which means it’s the season for test announcements by EDA companies. Synopsys made some noise, but not with one big blockbuster new thing; rather they assembled a couple of newsy bits that, summed together, merit some discussion.
Just to organize my thinking here, so that I don’t get us lost, there are two basic announcements: Cell-aware+Slack-based testing and STAR for eFLASH. The first involves two subtopics that we should review first.
Cell Awareness
Critical to any test strategy is the notion of coverage. Did you cover all the things that could go wrong? Well, that question leads to another immediate one: “What are all the things that can go wrong?” And this brings us to the world of fault modeling.
Back in a more innocent time, this was easy. You assumed that a fault meant that some line was either broken (so it wouldn’t receive a signal sent to it and would be stuck at some value) or shorted to VCC (outdated “CC” intentional) or ground. And so we had “stuck-at” faults. Nice, but far from comprehensive. (It’s no fair claiming high test coverage by using a model that exposes few faults.)
Since then, fault coverage models have become much more elaborate, including lines bridged together and resistive shorts and such. And those are just the static faults. We also do dynamicfaults for at-speed testing: signals arrive at the right value, but they take too danged long to do so.
These kinds of models depend on the logic of the function being tested. You can create a black box and generate the list of faults to be covered, but those faults are uninfluenced by how the circuits are physically laid out. Line adjacencies and such can create the risk of specific faults that can’t necessarily be intuited from outside a black box. Fin defects are another specific target for this. You might get lucky and find that the new faults are already accounted for in your existing set of tests, but you can’t count on it.
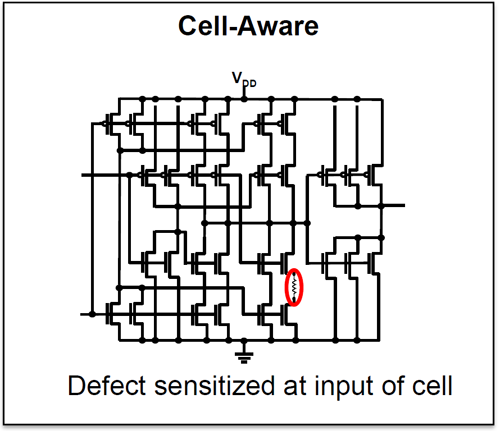
(Image courtesy Synopsys)
This is what Synopsys refers to as cell-aware modeling, and we took a more detailed look at it a few years ago. We’ll keep things at this higher-level review stage here: according to the cells you use, specific additional faults (and tests to find them) will be added that stress the idiosyncratic weaknesses of those particular cells.
Synopsys also has a utility to identify possible cell-aware issues. It’s not an auto-generator, but it does identify fault candidates, from or to which a test engineer can remove or add faults.
Slacking
Meanwhile, over in another corner, we have what Synopsys refers to as slack-based testing. This is something we haven’t looked at in the past in any detail, although, in and of itself, it’s not new.
The idea is that a fault along a path that branches farther down the line may cause a fault along one branch and not the other. Here we’re talking timing faults – some sort of soft defect that causes a slow-down. The idea is pretty straightforward: if one of the two branches is closer to its timing limit (i.e., has less timing slack), then an upstream slow-down is more likely to cause that branch to fail timing, rather than another branch that has more margin.
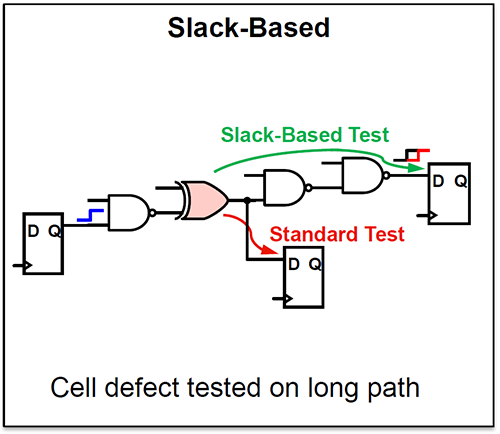
(Image courtesy Synopsys)
Pretty straightforward. Except that, apparently, standard test algorithms pick the shortest branch – that is, the highest-slack branch – for observation. Because that branch has more margin, it might forgive a slight delay upstream, so you might not notice that there is this delay. That is, until the longer branch fails in a system somewhere. Which isn’t particularly helpful.
So slack-based testing involves taking the longest, or lowest-slack, branch and testing it instead. Note, however, that this applies only to faults occurring before the branch between two paths. If there are faults on the individual paths after the branch, you’d need to test for those separately. Of course, you’ve already tested the longest path, so one test captures faults both before and after the branch, as shown below (Fault sites 1 and 2 between nodes a and c).
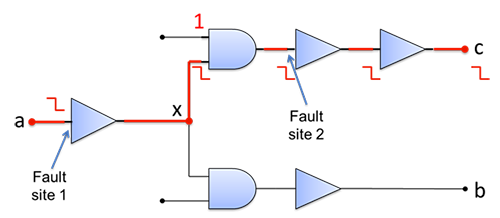
(Image courtesy Synopsys)
Note, however, that, thanks to the magic of converging (or reconverging) logic, Fault 2 may also lie along another path. It might be that Fault 2 doesn’t push path a-c beyond its limit, but it also needs to be tested for the other path that includes it – it might break that one.
The figure below shows an alternative path that not only includes Fault 2, but another fault on a gate shared with the a-c path, but not tested along the a-c path. Even in the absence of Fault 3, if the path that comes in via that AND gate has less slack than the a-c path, then Fault 2 on its own might cause a failure even if it doesn’t do so on the a-c path. So that second branch may still need some more tests if those faults are not already covered.
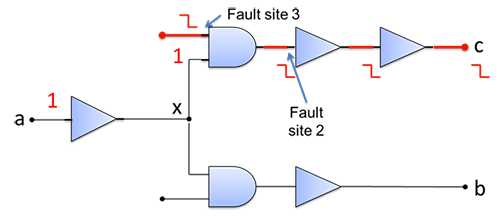
(Image courtesy Synopsys)
Cell-Aware Slacking
Neither the cell-aware nor the slack-based methodology is new. But we review them because of what is new. In the past, they’ve been disconnected, separate approaches. In particular, slack-based testing wasn’t incorporated into cell-aware testing. Or vice versa.
And now they are. In other words, when looking for a cell-aware fault, a slack-based approach can now be utilized.
Of course, then there’s the “be careful what you wish for” syndrome. It would be a bit of an ethical dilemma if you found that you were missing a ton of defects, and [yay] now you’ve identified tests for them, but [boo] it means a ton more tests and lots more test time. Do you spend the money to improve the quality?
Fortunately for Synopsys, their early customer data suggests that this isn’t an issue. In one example, the existing test creation came up with 6119 tests; adding the cell-aware-slack-based tests increased that number by only 121.
Starring eFlash
On a separate note, Synopsys markets a memory-testing infrastructure that they refer to as the STAR Memory System. Its goal is to wrap embedded memory arrays with testability logic for complete memory coverage using a minimum of overhead. It also makes these buried memories accessible to external test equipment. (We saw how a similar approach was applied to IP last year.)
All good, except for one thing: it didn’t include eFlash. Well, this year it does. They’ve added wrappers and logic that support the testing of eFlash.
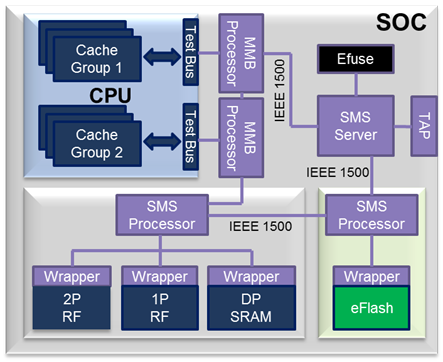
(Image courtesy Synopsys)
Why is this necessary? Well… for the same reason that it’s necessary to test other types of embedded memory. But if that’s not enough for you, Synopsys adds one more concrete reason: because the automotive standard (ISO 26262) requires the ability to do in-field diagnostics. So without this STAR support, Synopsys couldn’t do that. With STAR, they can.
More info:
TetraMAX ATPG (cell-aware/slack-based testing)





What do you think about Synopsys’s new test additions?